
O pré-treinamento de modelos modernos de grandes linguagens (LLMs), muitas vezes com até 100 bilhões de parâmetros ou mais, normalmente envolve milhares de aceleradores e grandes corpora de tokens que duram dias ou meses. Nessa escala, o sucesso normalmente se resume a dois resultados principais.
- velocidade: A taxa na qual o sistema consome dados de treinamento (geralmente medido em tokens/segundo)
- aprendizado: quanto progresso é alcançado por unidade de tempo, geralmente monitorado por meio de perdas e tempo de parede.
Este artigo coloca intencionalmente entre colchetes o eixo aprendizagem/qualidade. Isso se concentra em questões de sistemas. O que “rápido” realmente significa no treinamento de dicionário em larga escala e como você mede isso de maneira independente da carga de trabalho?
A taxa de transferência bruta (tokens/seg) é necessária. No entanto, é sensível à situação. Depende de hiperparâmetros como número de GPUs, topologia de rede, largura de banda de armazenamento, formato de dados, comprimento de sequência, arquitetura de modelo e tamanho global de lote.
Em outras palavras, o rendimento é um resultado, não uma medida normalizada de eficiência. As métricas que sobrevivem à comparação de vários conjuntos de treinamento e orientam as prioridades de engenharia exigem uma lente de eficiência que expresse o progresso como parte da capacidade realizada, em vez de velocidade absoluta.
Espaço de coworking da cidade de TNW – onde o melhor trabalho acontece
Um espaço de trabalho projetado para crescimento, colaboração e oportunidades infinitas de networking no centro da tecnologia.
Esta é a motivação por trás do goodput. Vá de “Quantos tokens por segundo você está observando?” “Que percentagem do potencial do sistema foi convertida em progresso útil de formação?” O Google introduziu oficialmente o Goodput de produtividade de ML como uma métrica de eficiência para sistemas de treinamento ponta a ponta, fornecendo uma abordagem baseada em API para diagnosticar fontes de goodput (perda de produtividade) e calcular goodput em toda a pilha.
Do rendimento ao bom rendimento: por que a normalização é importante
O rendimento é fácil de registrar e comunicar, mas integra vários fenômenos independentes.
- confiável: A tarefa pode continuar a operar ou será reiniciada repetidamente?
- Recuperação e resiliência: Se ocorrer uma falha, quanto progresso será perdido e com que rapidez será retomado?
- eficiência computacional: Quando uma tarefa está “em execução”, a GPU realmente executa a matemática do modelo com eficiência ou é subutilizada devido a atrasos e sobrecarga?
Uma execução de pré-treinamento pode parecer “rápida” (tokens altos/segundo quando normal), mas ainda pode ser “lenta” na conclusão do relógio se for interrompida com frequência, restaurada lentamente ou executada com baixa eficiência computacional.
O valor central do goodput é que ele permite que a pilha conte explicitamente o tempo perdido e o desperdício de computação e atribua essas perdas.
O que é treinar Goodfoot?
Train Goodput é a porcentagem da capacidade de treinamento teórico que é convertida em progresso de treinamento útil. Na verdade, este é um número. (0,1)onde:
- 1,0 significa: Correr é consistentemente produtivoNão há perda de tempo significativa devido a interrupções, recuperação, sobrecarga de pontos de verificação ou subutilização de computação.
- 0,5 significa Aproximadamente metade do potencial está sendo desperdiçadoMuitas vezes, eles ficam invisíveis durante períodos de inatividade, reinicializações, interrupções ou sobrecarga.
O enquadramento do Google enfatiza que o goodput deve ser acionável. Ou seja, uma análise decomponível que explica não apenas as métricas principais, mas também onde o tempo foi perdido (badput) e por quê.
Para tornar a decomposição concreta para o pré-treinamento LLM, é útil descrever uma pilha de treinamento de três camadas.
- Camada de infraestrutura (cluster, orquestração, tempo de execução, tratamento de erros)
- Camada de estrutura (tempo de execução de treinamento distribuído, pontos de verificação, gerenciamento de estado, inicialização)
- Camada de programa/modelo (estratégia de paralelismo, kernel, precisão, esquema de lote/sequência, ou seja, quão eficientemente a matemática é mapeada para o hardware)
Isto é consistente com a forma como as grandes organizações educacionais realmente funcionam. Equipes diferentes possuem hierarquias diferentes e precisam de atribuições claras para melhorar a eficiência.
Camada 1: Infra Goodput – “Com que frequência estamos realmente treinando?”
Goodput de infraestrutura captura a disponibilidade. Ou seja, a porcentagem de tempo que um trabalho passa realmente em um estado de treinamento saudável, em vez de ficar inativo devido a uma falha na infraestrutura ou a um atraso na orquestração.
Uma definição operacional simples para a janela de medição (W) é:
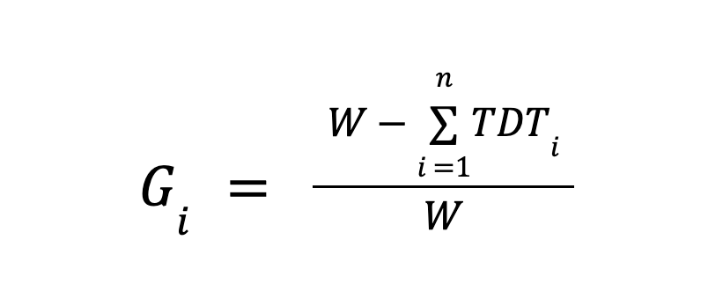
onde:
- TDTmeu = tempo de inatividade da carga de trabalho de treinamento na i-ésima interrupção
- W = janela de tempo de medição Goodput (por exemplo, 24 horas)
- n = número de interrupções de treinamento no período W
Isso captura o que importa às equipes de infraestrutura: detecção de falhas, isolamento, resolução e latência de reinicialização. Clusters do mundo real falham de maneiras não triviais em escala. A literatura sobre confiabilidade mostra que à medida que a escala da tarefa aumenta, as vulnerabilidades no nível da tarefa aumentam e a confiabilidade deve ser projetada como um problema de camada cruzada, em vez de “apenas hardware”.
Camada 2: Framework Goodfoot – “Quanto progresso eu perco se falhar?”
A disponibilidade da infraestrutura não é tudo. Mesmo com o reinício rápido, o progresso do treino pode ser perdido dependendo de como o estado é salvo e restaurado. É aqui que entra o Framework Goodfoot. Ele mede a porcentagem de tempo que não é perdido devido à sobrecarga do ponto de verificação e ao desperdício de recuperação.
Acima da janela (W):

Esta equação levanta um ponto importante que está oculto apenas no rendimento. Embora os pontos de verificação sejam um fardo constante, os erros geralmente impõem penalidades separadas que incluem sobrecarga de reinicialização e desperdício de reversão.
Os pontos de verificação não são “resiliência gratuita”.
No treinamento distribuído em larga escala, os pontos de verificação podem dominar a sobrecarga de E/S e de coordenação. No entanto, checkpoints pouco frequentes aumentam as perdas de reversão. Portanto, o fluxo do ponto de verificação “correto” é uma compensação típica do sistema. Ou seja, minimizamos (SST) a previsão (LST) em vez de aumentá-la.
Camada 3: Modelo Goodfoot – “Estamos transformando o silício em matemática de forma eficiente?”
Mesmo execuções de treinamento perfeitamente estáveis e recuperáveis podem ser ineficientes se as GPUs forem subutilizadas. A métrica padrão aqui é a utilização do modelo FLOP (MFU), que mede a eficácia com que o programa de treinamento converte os recursos do acelerador de pico nos FLOPs necessários para a propagação direta e reversa do modelo.
Fórmula prática de MFU:
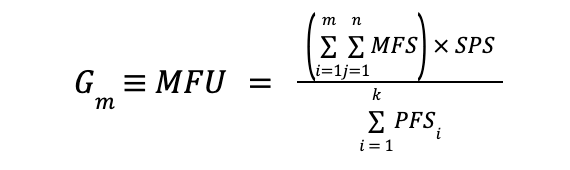
onde:
- MFS = FLOPs do modelo calculado por parâmetro, por token, por etapa
- m = número de parâmetros do modelo que podem ser aprendidos
- n = número de tokens de entrada
- SPS = passos observados por segundo
- PFSmeu = máximo teórico de FLOPs por segundo para a GPU
- k = número de GPUs participantes
O MFU é amplamente utilizado para relatar a eficiência do treinamento e é frequentemente definido como “a velocidade de computação do modelo observada dividida pela velocidade de computação máxima teórica”. O MFU baixo geralmente não é um único “bug”, mas um efeito urgente de:
- Sobrecarga de comunicação que domina o tempo da etapa (redução total/coleta total)
- Configuração de paralelismo inválida (incompatibilidade de TP/PP/DP/EP)
- Microlotes muito pequenos (preenchimento insuficiente do kernel) ou práticas inadequadas de sequenciamento/posicionamento
- Largura de banda de memória e pressão de estado de ativação/otimização
- Falta de sobreposição de comunicação com a computação
A escolha das “camadas de programa” é importante, incluindo DDP e FSDP, seleção de TP/PP, paralelismo especializado para MoE, precisão (BF16/FP8), tamanhos globais e de microlotes e agendamento cuidadoso de tarefas coletivas.
Boa capacidade de treinamento combinado: métricas de eficiência em nível de pilha
Com boas contribuições dos três níveis hierárquicos, a eficiência do treinamento ponta a ponta pode ser definida como:
Treinando Goodfoot (Gchá) =Gmeu GF Gmeio
onde:
- Gmeu = Infraestrutura Goodfoot
- GF = Estrutura Goodfoot
- Gmeio = Modelo Goodfoot
Este único número ((0,1)) é útil porque reconhece a pilha.
Como realmente medir o goodput
A Goodput é tão confiável quanto sua instrumentação. Uma pilha de medição prática normalmente inclui:
1. Configure a janela de medição.
Use um período de tempo fixo (24 horas é típico para relatórios operacionais) e (Gmeu, GF, Gmeio) para manter a consistência da propriedade durante o mesmo período de tempo.
2. Documente explicitamente “tempo de ensino produtivo”.
Registre os limites das fases e as transições de estado “ativas no trem”. As estruturas Goodput são geralmente separadas. produtivo hora maldade Categorias como travamentos, reinicializações, sobrecarga de pontos de verificação e outros intervalos improdutivos. (Google nuvem)
3. Associe cada interrupção a um evento de erro.
O trabalho de confiabilidade propõe mensurar a falha através da classificação e relacioná-la com a perda de tempo efetivo de treinamento. Isto é útil para a responsabilização e para prever como as taxas de falha aumentam com a escala da operação.
4. Calcule o MFU a partir do treinamento em estado estacionário.
A menos que seu objetivo explícito seja “MFU misto”, exclua preparação, avaliação, longas pausas nos pontos de verificação e períodos de recuperação ao estimar o MFU. MFU é mais útil como lente de eficiência computacional em condições de estado estacionário.
conclusão
O aprendizado de dicionário LLM em larga escala é fundamentalmente um problema de sistemas distribuídos que envolve problemas matemáticos massivamente paralelos.
O rendimento (tokens/seg) merece manchetes, mas não é uma medida confiável de eficiência em relação à pilha ou ao tempo.
Goodput fornece uma alternativa normalizada e decomponível. Isto quantifica a proporção da capacidade potencial de treinamento que é convertida em progresso real de treinamento e atribui a perda às camadas que podem realmente corrigi-la.
Como enfatizam os estudos de confiabilidade e as plataformas de treinamento de produção, o treinamento de escalonamento tem tanto a ver com a redução de desperdícios quanto com o aumento do rendimento máximo, e tratar a eficiência como um atributo da pilha, em vez de uma única métrica, produzirá os benefícios mais duradouros.
Quando você constrói ou opera um sistema de ML em grande escala e começa a pensar em termos de goodput no nível da pilha, em vez de tokens por segundo, há um trabalho mais profundo a ser feito na forma como a infraestrutura, a estrutura e o design do modelo interagem.
Para discussões contínuas sobre eficiência de treinamento em larga escala, plataformas de ML resilientes e infraestrutura de IA centrada em produtos, conecte-se em: Anirban Roy para Linkedin. Você também pode explorar seu protótipo de interação de IA em: LLMProxy.ai
Referências:
- Google Cloud: métricas Goodput para medir a produtividade de ML (Google Cloud)
- AWS: treinamento sem checkpoint para Amazon SageMaker HyperPod (Amazon Web Services, Inc.)
- Kokolis et al.: Repensando a confiabilidade em um cluster de pesquisa de aprendizado de máquina em grande escala (arXiv)



{kind=link}